1. Apache Spark简介
Apache Spark是一款轻量级快速统一分析引擎。作为一个开源的大数据处理框架,Spark围绕速度,易用性和复杂分析能力而构建。开发人员在处理大量数据或处理内存有限和时间过长时通常会使用Spark。
1.1. 超快的速度
Apache Spark在批量数据和流量数据处理方面都实现了高性能,并提供了优异的调度器、查询器和物理执行引擎给大家使用。例如下图,Spark比Hadoop运行工作负载的速度提高了100倍。

1.2. 简单易用
Spark提供了80多个高级操作器,可轻松构建并行应用程序。您可以使用Scala,Python,R和SQL Shell与Spark进行交互。
1 | df = spark.read.json("logs.json") df.where("age > 21") |
1.3. 通用性
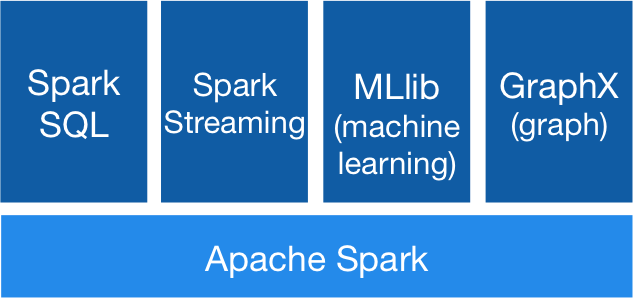
Spark可以结合SQL,流和复杂的分析一起使用。Spark为包括SQL和DataFrames,用于机器学习的MLlib,GraphX和Spark Streaming在内的库提供了强大的支持。您可以在同一应用程序中无缝组合这些库。
1.4. 随处运行
Spark可在Hadoop,Apache Mesos,Kubernetes,独立或云中运行。它可以访问各种数据源。您可以在EC2,Hadoop YARN,Mesos或Kubernetes上使用独立集群模式运行Spark。访问HDFS,Alluxio,Apache Cassandra,Apache HBase,Apache Hive和数百种其他数据源中的数据。

2. Spark实战章节
第一篇: Apache Spark Standalone集群模式部署

