1. 环境准备
为了部署Apache Spark Standalone集群模式,本次准备了三台Linux虚拟机来实现集群:一台Master和两台Slaves。
Master: 192.168.71.130
Slave: 192.168.71.131
Slave: 192.168.71.132
为了保证三台虚拟机之间能正常访问通讯,需要在每台虚拟机上配置/etc目录下的hosts和hostname文件。
所有的hosts文件设置如下:
1 | hadoop0 192.168.71.130 |
各自对应IP的虚拟机上的hostname设置成上面相对应的IP地址前面的别名,例如IP为192.168.71.130的虚拟机的hostname设置成hadoop0。然后,通过ping命令测试各节点之间是否互通。
如果各节点之间有使用密钥验证登录,那么需要额外的生成密钥并添加到各节点认证文件中,以实现各节点的免密登录。
生成密钥:
1 | ssh-keygen |
一路默认回车,这样在当前用户的主目录下会生成.ssh文件夹。进入这个文件夹,首先把本机的公钥加入认证文件:
1 | cat id_rsa.pub >> authorized_keys |
2. 下载Spark
接下来,我们去Apache Spark官网下载相对应的Spark Pack。这里我们选择2.4.4 release版本并预编译包含Hadoop2.7的lib库的Spark。(Spark下载地址)
这里我们选择包含hadoop的lib库的Spark是为了免去配置Spark所需的hadoop依赖库的繁琐过程,具体的不带hadoop lib库的Spark的手动配置过程,会在Spark与Hadoop的整合应用这一章再展开。
然后点击下载链接,进入跳转页面后,任意选择一个下载链接。接着在预先准备的Linux虚拟机上下载Spark Package, 例如:
1 | wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz |
在/etc/profile中添加SPARK_HOME路径:
1 | vi /etc/profile |
3. 配置Spark Master
在准备好Spark Package之后,我们上Master节点(192.168.71.130),进行相应的配置。
首先我们进入Spark目录spark-2.4.4-bin-hadoop2.7,然后配置spark环境变量,修改conf/spark-env.sh文件,在文件末尾添加JAVA_HOME路径(指定所使用的JDK)。
1 | cp conf/spark-env.sh.template conf/spark-env.sh |
接着配置slave机器的信息,修改conf/slaves文件,在文件末尾添加集群各台主机的hostname:
1 | cp conf/slaves.template conf/slaves |
4. 配置Spark Workers (Slaves)
当Spark Master配置完成后,配置各个Spark Workers相对比较简单。这里使用linux的scp命令直接在各主机节点的局域网内床送复制SparK Pack程序文件。
例如在节点192.168.71.131和192.168.71.132上执行如下命令:
1 | scp root@192.168.71.130:/home/guty/software/spark-2.4.4-bin-hadoop2.7 /home/guty/software |
同样,在节点192.168.71.131和192.168.71.132上/etc/profile文件中添加SPARK_HOME路径。
5. 启动和停止Spark
启动Spark
启动后会显示如下信息:1
2
3
4
5
6./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/guty/software/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop0.out
hadoop2: starting org.apache.spark.deploy.worker.Worker, logging to /home/guty/software/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop2.out
hadoop1: starting org.apache.spark.deploy.worker.Worker, logging to /home/guty/software/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop1.out
hadoop0: starting org.apache.spark.deploy.worker.Worker, logging to /home/guty/software/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop0.out然后可以访问Spark Web UI界面,http://192.168.71.130:8080是Spark Master节点web界面,下图可以看到各个workers节点的列表信息:
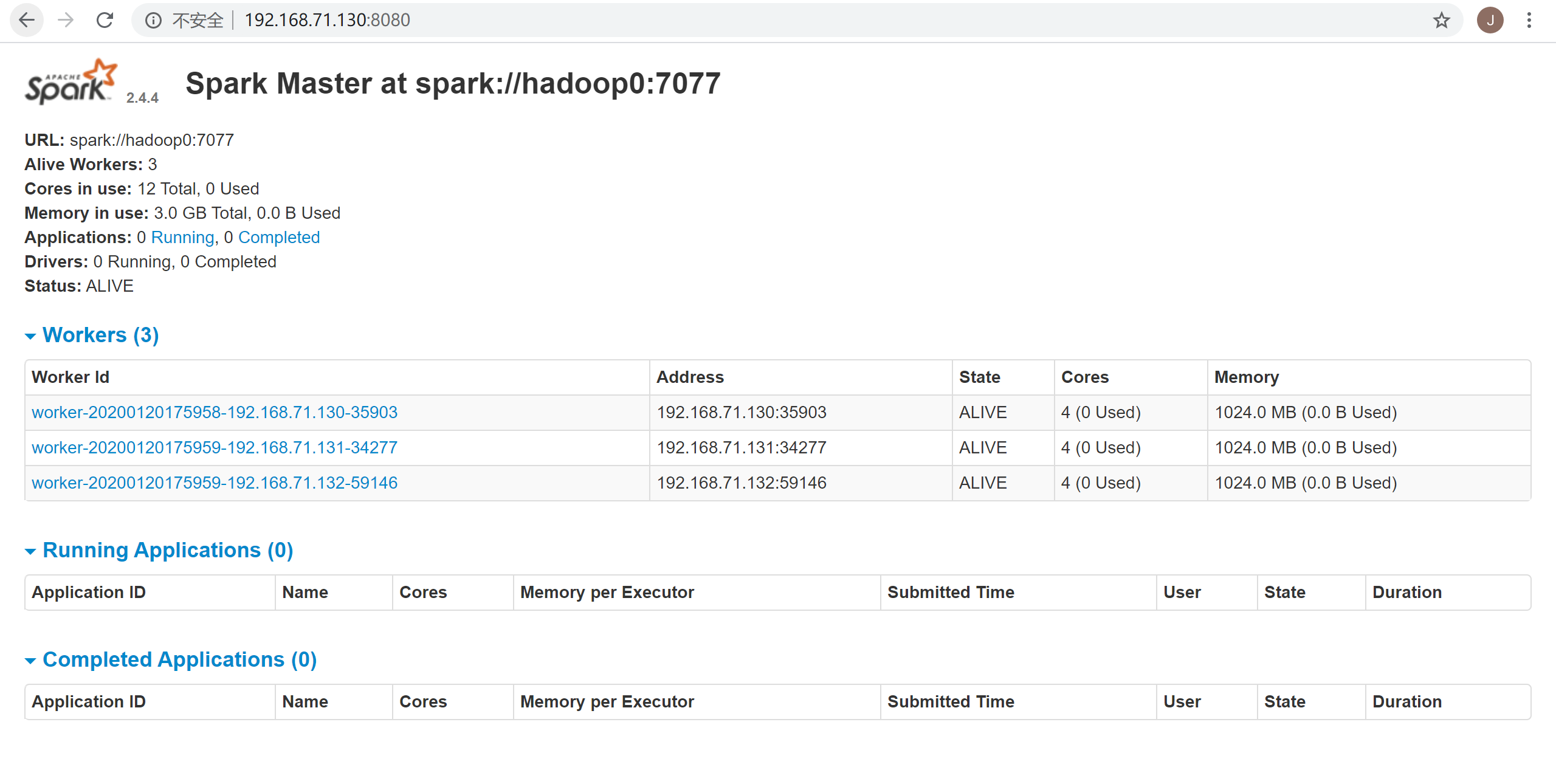
单击上图其中某一个worker节点,可以查看该worker节点的任务执行情况,如下图:
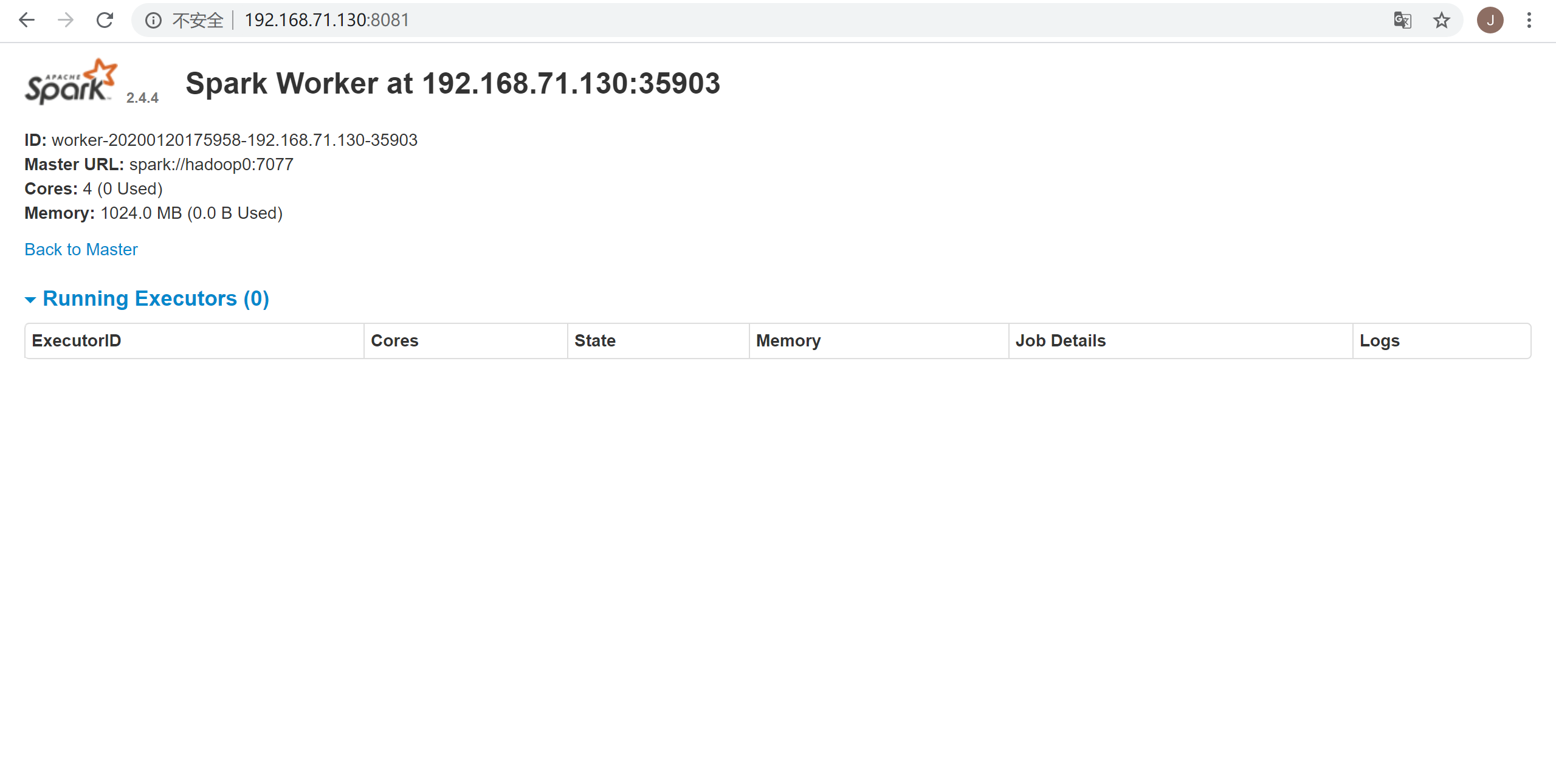
停止Spark
停止Spark会显示如下信息:1
2
3
4
5
6./sbin/stop-all.sh
hadoop1: stopping org.apache.spark.deploy.worker.Worker
hadoop0: stopping org.apache.spark.deploy.worker.Worker
hadoop2: stopping org.apache.spark.deploy.worker.Worker
stopping org.apache.spark.deploy.master.Master

